Kafdrop is an open source, web based user interface designed for monitoring and managing Apache Kafka clusters. It provides a lightweight, intuitive dashboard to visualize Kafka brokers, topics, partitions, consumer groups, and message contents, making it an excellent tool for developers, DevOps engineers, and system administrators who need to interact with Kafka without relying on command-line tools. Built on Spring Boot, Kafdrop supports advanced features like browsing messages in JSON, Avro, or Protobuf formats, and it integrates seamlessly with secured Kafka clusters using protocols like SASL or TLS. Since version 3.10.0, Kafdrop no longer requires ZooKeeper, leveraging Kafka’s native protocol for metadata, which simplifies deployment.
Kafdrop is highly flexible and can be deployed in various ways: as a standalone Java application (JAR), a Docker container, or within a Kubernetes cluster. Its lightweight nature makes it suitable for development, testing, and production environments. However, to ensure smooth operation, it’s critical to understand its system requirements, which vary depending on the deployment method, Kafka cluster size, and usage patterns.
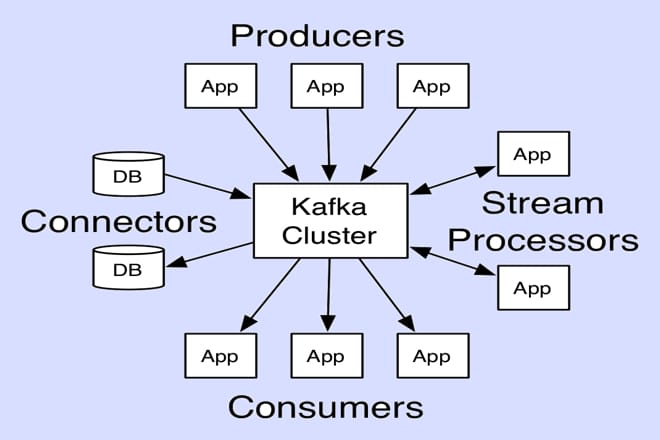
Kafdrop’s Functionality
Before diving into the system requirements, it’s worth understanding what Kafdrop does and why its requirements are relatively modest. Kafdrop is not a Kafka broker or a storage system; it’s a client-side tool that connects to an existing Kafka cluster to retrieve and display metadata and messages. Its primary functions include:
- Broker Monitoring: Displays the status, IDs, and host/port details of Kafka brokers in the cluster.
- Topic Management: Lists topics, their partitions, replication factors, and configurations.
- Message Browsing: Allows viewing of messages in topics with support for JSON, Avro, and Protobuf deserialization.
- Consumer Group Insights: Shows consumer group offsets, lag, and member details.
- Security Integration: Supports SASL, SSL/TLS, and schema registries for secure and schema-based Kafka setups.
Because Kafdrop is a read-heavy tool that queries Kafka’s metadata and messages, its resource demands are primarily tied to the size of the Kafka cluster, the volume of messages being browsed, and the complexity of the UI interactions. This context informs the system requirements discussed below.
Software Requirements for Running Kafdrop
Kafdrop’s software dependencies are straightforward, reflecting its design as a Java-based, Spring Boot application. Below is a detailed breakdown of the software requirements, including version compatibility, optional dependencies, and configuration considerations.
Java Runtime Environment (JRE)
- Requirement: Java 11 or higher (Java 17+ recommended).
- Details: Kafdrop is a Spring Boot application, which relies on the Java Virtual Machine (JVM) to execute. Java 11 is the minimum supported version for recent releases (e.g., Kafdrop 3.x series), as it provides long-term support (LTS) and compatibility with modern Spring Boot versions. For optimal performance and security, Java 17 or later is recommended, especially for production environments.
- Notes:
- Older versions of Kafdrop (pre-3.0) may work with Java 8, but this is not recommended due to end-of-life support for Java 8 and potential compatibility issues with newer Kafka client libraries.
- Ensure the JAVA_HOME environment variable is set correctly, and the java command is accessible in your system’s PATH.
- For resource-constrained environments, lightweight JVM distributions like Eclipse Temurin or Amazon Corretto are viable options.
Apache Kafka Compatibility
- Requirement: Apache Kafka 0.11.0 or later.
- Details: Kafdrop connects directly to Kafka brokers using the Kafka protocol, specified via the –kafka.brokerConnect flag (e.g., localhost:9092). It supports all Kafka versions from 0.11.0 onward, as this version introduced the necessary admin APIs for metadata retrieval without ZooKeeper.
- Notes:
- Ensure your Kafka cluster is accessible from the machine running Kafdrop. This may require firewall rules or network configurations to allow communication on the Kafka broker ports (default: 9092).
- Kafdrop supports secure Kafka clusters using SASL (e.g., PLAIN, SCRAM-SHA-256) or SSL/TLS. You’ll need to provide security configurations (e.g., security.protocol, sasl.mechanism) via environment variables or Kafka properties.
- For Avro or Protobuf message browsing, Kafdrop can integrate with a Schema Registry (e.g., Confluent Schema Registry). You’ll need to specify the registry URL via –schemaregistry.connect.
Operating System
- Requirement: Any OS that supports Java (Linux, macOS, Windows).
- Details: Kafdrop is platform-agnostic due to its Java-based architecture. Common choices include:
- Linux: Preferred for production deployments (e.g., Ubuntu, CentOS, Debian). Linux is lightweight, widely supported, and commonly used in Kafka ecosystems.
- macOS: Suitable for development and testing, especially for developers using macOS workstations.
- Windows: Supported for development or lightweight testing, but less common in production due to resource overhead.
- Notes:
- Linux is recommended for production due to its stability, performance, and compatibility with containerized deployments (e.g., Docker, Kubernetes).
- For Windows, ensure compatibility with Java and any container runtime if using Docker.
ZooKeeper (Not Required)
- Requirement: None (since Kafdrop 3.10.0).
- Details: Earlier versions of Kafdrop required ZooKeeper to retrieve Kafka metadata, as Kafka relied on ZooKeeper for cluster coordination. Since Kafka 2.8.0 introduced ZooKeeper-less operation (via KRaft mode) and Kafdrop 3.10.0 adopted direct broker communication, ZooKeeper is no longer a dependency.
- Notes:
- If you’re using an older version of Kafdrop (pre-3.10.0), you’ll need ZooKeeper running and accessible, with the –zookeeper.connect flag configured (e.g., localhost:2181).
- For modern Kafka clusters using KRaft, ensure Kafdrop is updated to at least 3.10.0 to avoid ZooKeeper dependency.
Docker (Optional)
- Requirement: Docker 20+ or equivalent (e.g., Podman).
- Details: For containerized deployments, Kafdrop provides an official Docker image (obsidiandynamics/kafdrop:latest). Docker is not required for standalone JAR deployments but is highly recommended for simplified setup and scalability.
- Notes:
- Ensure Docker is installed and running. For Linux, follow your distribution’s package manager instructions (e.g., apt install docker.io for Ubuntu).
- On macOS/Windows, use Docker Desktop.
- Known issue: Avoid Docker versions >4.26.1 on Apple M1/M2 chips due to compatibility issues with the Kafdrop image. Use an earlier version or Podman as a workaround.
- Example command: docker run -d -p 9000:9000 -e KAFKA_BROKERCONNECT=localhost:9092 obsidiandynamics/kafdrop.
Web Browser
- Requirement: Modern web browser (e.g., Chrome, Firefox, Edge, Safari).
- Details: Kafdrop’s UI is accessed via a web browser at (default port, configurable). Any recent browser version supports the HTML/CSS/JavaScript used by Kafdrop’s frontend.
- Notes:
- Ensure the machine running Kafdrop has port 9000 (or your configured port) open for browser access.
- For remote access, configure firewall rules or use a reverse proxy (e.g., Nginx) to expose the UI securely.
Optional Dependencies
- Schema Registry: Required for Avro or Protobuf message deserialization. Configure via –schemaregistry.connect).
- Security Configurations: For SASL/SSL, provide Kafka properties (e.g., base64-encoded kafka.properties file via KAFKA_PROPERTIES environment variable).
- Prometheus/JMX: For monitoring Kafdrop itself, enable JMX metrics and integrate with Prometheus (optional, requires additional configuration).
Hardware Requirements for Running Kafdrop
Kafdrop is designed to be lightweight, as it doesn’t store data or process Kafka messages directly it only queries and displays information from the Kafka cluster. However, hardware requirements depend on the deployment method, the size of the Kafka cluster, and the intensity of UI interactions (e.g., browsing large topics). Below are the recommended hardware specifications.
CPU
- Minimum: 1 core (e.g., Intel/AMD x86_64 or ARM-compatible).
- Recommended: 1-2 cores for production.
- Details: Kafdrop’s CPU usage is minimal for basic operations like fetching broker metadata or topic lists. However, CPU demand increases when:
- Browsing large topics with many messages.
- Deserializing complex Avro/Protobuf messages.
- Handling high-frequency UI requests in multi-user environments.
- Notes:
- For development or small clusters (<10 topics, low message volume), a single core is sufficient.
- In production, allocate 1-2 cores to handle concurrent users or large-scale clusters (>100 topics, high throughput).
- For Kubernetes, set CPU requests/limits (e.g., 100m request, 500m limit) to ensure resource allocation.
RAM
- Minimum: 64-128 MB.
- Recommended: 256-512 MB for typical use; 1-2 GB for heavy usage.
- Details: Kafdrop’s memory footprint is determined by the JVM heap size, configured via -Xms and -Xmx flags (e.g., -Xms32M -Xmx128M for minimal setups). Memory usage scales with:
- Number of topics/partitions being queried.
- Volume of messages displayed in the UI.
- Use of schema deserialization (Avro/Protobuf).
- Notes:
- For development or small clusters, 64-128 MB is sufficient (e.g., -Xms32M -Xmx64M).
- For production with large clusters or frequent message browsing, allocate 512 MB to 2 GB to avoid garbage collection pauses.
- In Docker/Kubernetes, set memory limits (e.g., 128Mi request, 512Mi limit) to prevent overconsumption.
Storage
- Minimum: ~50-100 MB.
- Recommended: 100-200 MB for flexibility.
- Details: Kafdrop itself requires minimal storage:
- The JAR file is ~50 MB.
- The Docker image is ~100-150 MB.
- No persistent storage is needed unless caching messages or logs locally.
- Notes:
- For Avro/Protobuf, mount schema files if not using a Schema Registry, which may require additional storage.
- Log files (if enabled) can grow; configure log rotation to manage disk usage.
- In Kubernetes, use emptyDir or a small PVC for logs if needed.
Network
- Requirement: Stable connection to Kafka brokers; port 9000 for UI access.
- Details: Kafdrop requires network access to:
- Kafka brokers (default port 9092, or as configured).
- Schema Registry (if used, default port 8081).
- Web UI (default port 9000, configurable via –server.port).
- Notes:
- Ensure low latency between Kafdrop and Kafka brokers for responsive UI performance.
- For secure setups, configure SSL/TLS and open necessary ports.
- In production, use a load balancer or reverse proxy (e.g., Nginx, Traefik) for UI access.
Deployment Options and Their Requirements
Kafdrop supports multiple deployment methods, each with slightly different requirements. Below is a detailed look at the three primary options: standalone JAR, Docker, and Kubernetes.
Standalone JAR Deployment
- Use Case: Ideal for development, testing, or simple production setups.
- Requirements:
- Java 11+ installed.
- Kafka cluster accessible via bootstrap servers.
- ~50 MB disk space for the JAR.
- Minimal CPU/RAM (e.g., 1 core, 128 MB).
- Setup Steps:
- Download the latest Kafdrop JAR from the official releases page.
- Run with: java -jar kafdrop-3.x.x.jar –kafka.brokerConnect=localhost:9092.
- Access the UI at kafdrop.com.
- Configuration:
- Use command-line flags (e.g., –server.port, –schemaregistry.connect) or a kafdrop.properties file.
- Example: java -jar kafdrop.jar –kafka.brokerConnect=kafka:9092 –server.port=9001.
- Notes:
- Suitable for single-machine setups or lightweight environments.
- Manage as a background process using nohup or systemd for production.
Docker Deployment
- Use Case: Simplified deployment for development or production, especially in containerized environments.
- Requirements:
- Docker 20+ installed.
- Kafka cluster accessible.
- ~100-150 MB disk space for the image.
- Minimal CPU/RAM (e.g., 1 core, 256 MB).
- Setup Steps:
- Pull the image: docker pull obsidiandynamics/kafdrop:latest.
- Run the container: docker run -d -p 9000:9000 -e KAFKA_BROKERCONNECT=localhost:9092 obsidiandynamics/kafdrop.
- Access the UI at kafdrop.com.
- Configuration:
- Use environment variables (e.g., KAFKA_BROKERCONNECT, SERVER_PORT, KAFKA_PROPERTIES for security).
- Example for secure Kafka: docker run -d -p 9000:9000 -e KAFKA_BROKERCONNECT=kafka:9092 -e KAFKA_PROPERTIES=$(echo -n “security.protocol=SASL_SSL,sasl.mechanism=PLAIN” | base64) obsidiandynamics/kafdrop.
- Notes:
- Ideal for containerized environments or CI/CD pipelines.
- Ensure Docker networking allows access to Kafka brokers.
- Avoid Docker >4.26.1 on Apple M1/M2 due to compatibility issues.
Kubernetes Deployment
- Use Case: Scalable, production-grade deployments in Kubernetes clusters.
- Requirements:
- Kubernetes cluster (v1.20+ recommended).
- Kafka cluster accessible (within or outside the cluster).
- Resource requests/limits: ~100m CPU, 128Mi RAM (adjust based on usage).
- Setup Steps:
- Create a deployment YAML (example below).
- Apply with: kubectl apply -f kafdrop-deployment.yaml.
- Expose via a Service or Ingress for UI access.
Best Practices and Recommendations
- Use dedicated host/container: While Kafdrop is relatively lightweight, for production environments isolate it so that heavy UI usage doesn’t impact other services.
- Deploy close to Kafka cluster: For network performance, run Kafdrop in the same region/network segment as Kafka brokers.
- Enable HTTPS & restrict access: By default Kafdrop has no built-in authentication. Use a reverse proxy with OAuth/LDAP, or restrict access to trusted networks.
- Monitor Kafdrop itself: Use Actuator endpoints and metrics to monitor memory usage, JVM threads, GC, request latency.
- Limit message browsing in heavy clusters: Browsing large topics with many messages can strain the UI and backend. Consider limiting the number of messages returned or paging carefully.
- Cache metadata where possible: Frequently refreshing metadata (topics, partitions) can consume resources. Use caching or reduce refresh frequency if supported.
- Scale horizontally if needed: For large teams or heavy usage, deploy multiple instances of Kafdrop behind a load‐balancer.
- Keep version updated: Use the latest stable version of Kafdrop to benefit from performance improvements, bug fixes, security patches.
- Test configurations: Before production usage, simulate UI load and message browsing in a staging environment to size appropriately.
- Consider alternative tools for massive scale: If you have extremely large Kafka deployments (many thousands of topics/partitions), you may need more specialized tools; Kafdrop is great for inspection/administration but is not primarily a full-scale monitoring/alerting system.
Conclusion
In summary, running Kafdrop requires fairly modest software prerequisites (Java 17+, Kafka 0.11+), and hardware requirements scale with your Kafka cluster size and usage patterns. For a small setup you can get by with 1 vCPU and 1 GB RAM; for larger and production‐grade deployments you should provision multiple vCPUs, 4–8 GB+ RAM, SATA/SSD storage, proper networking, and monitor the resource usage.